text mining, digital humanities, embedding
Finding semantic neighbors with Orange
Ajda P. Žagar
Mar 28, 2025
Context
Recently, I attended a workshop on using AI, specifically text embeddings, in historical research. The workshop was held in the Hague and hosted by Pim Huijnen. His research group developed an interesting approach to retrieve relevant documents from a corpus. Imagine you'd like to study the concept of "progress" in political debates, but you don't want to limit your search to just the documents including the word "progress." Instead, you would also like to include those mentioning "progression", "advancement", or "development". You would also like to observe how this concept has changed through time.
To achieve this, Huijnen and colleagues suggest using existing word embedding models that consider the context of the word. The idea is that word embedding will differ depending on which words occur in their neighborhood. So if the word "progress" was originally mentioned more with, say, railway infrastructure, their early embeddings will be different to the later connection between "progress" and "technology". They propose:
- selecting candidate documents based on keyword search.
- using BERT-based embeddings that capture the semantic meaning of the sentence to numerically represent the document
- computing N closest neighbors to find semantically similar documents
- observing the document landscape, and
- observing how the association of the word with different concepts changes through time.
How to do it in Orange?
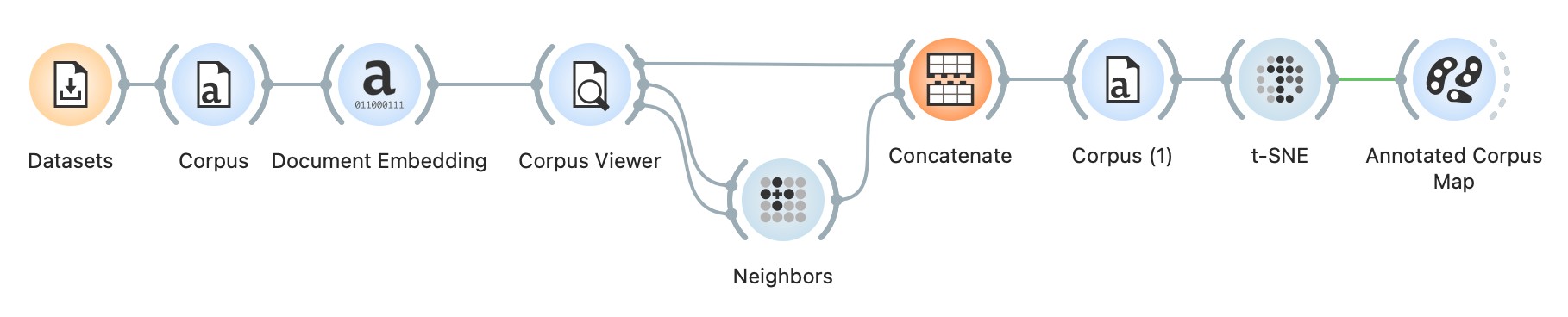
It is possible to construct a part of their proposed workflow in Orange. We start with the Datasets widget to select Parlamint, a subset of parliamentary speeches from the UK. Next, we use Corpus to indicate the text variable (content in our case) and embed the corpus with the Document Embedding multilingual sBERT model. We connect Corpus to Corpus Viewer to select candidate documents. For this example, we have selected \bprogress\b regular expression that finds all the mentions of the word progress. We have 47 documents that match our query.
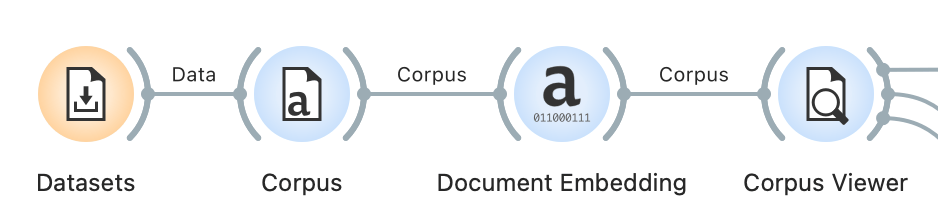
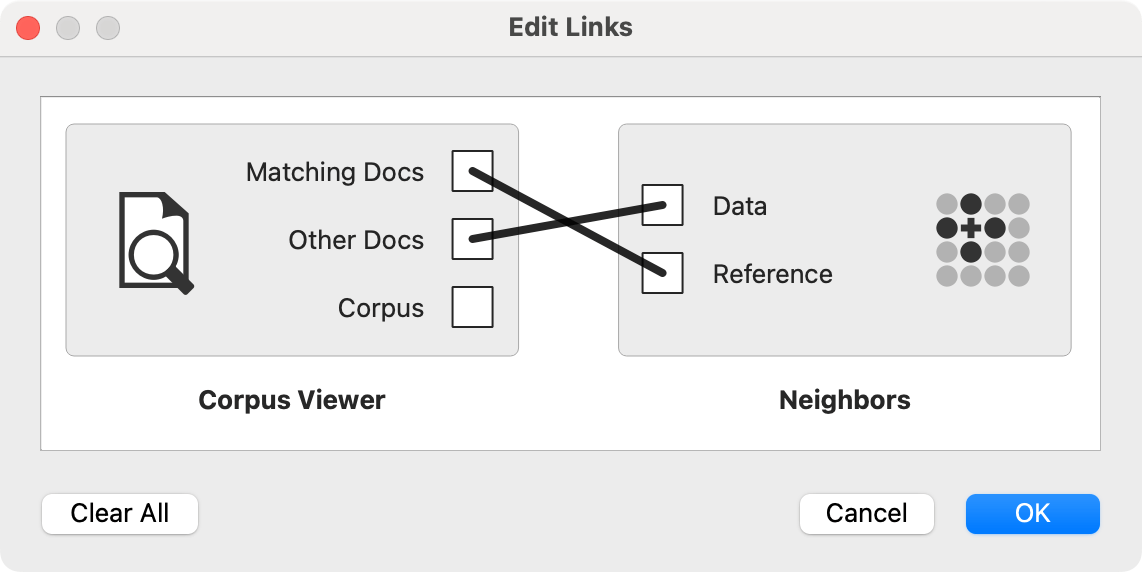
Now for the neighbor search. We wish to retrieve documents similar to our candidate documents. In other words, we wish to find documents that refer to progress in some other way, not explicitly using the word "progress". We will use Neighbors to achieve this. We use cosine distance to measure the similarity between documents and output 10 closest neighbors. Note that the input to Neighbors is a bit complicated. We need to input the Matching Data from Corpus Viewer as a reference data set (what the output needs to be similar to) and Other Docs as data (where the neighbors come from).
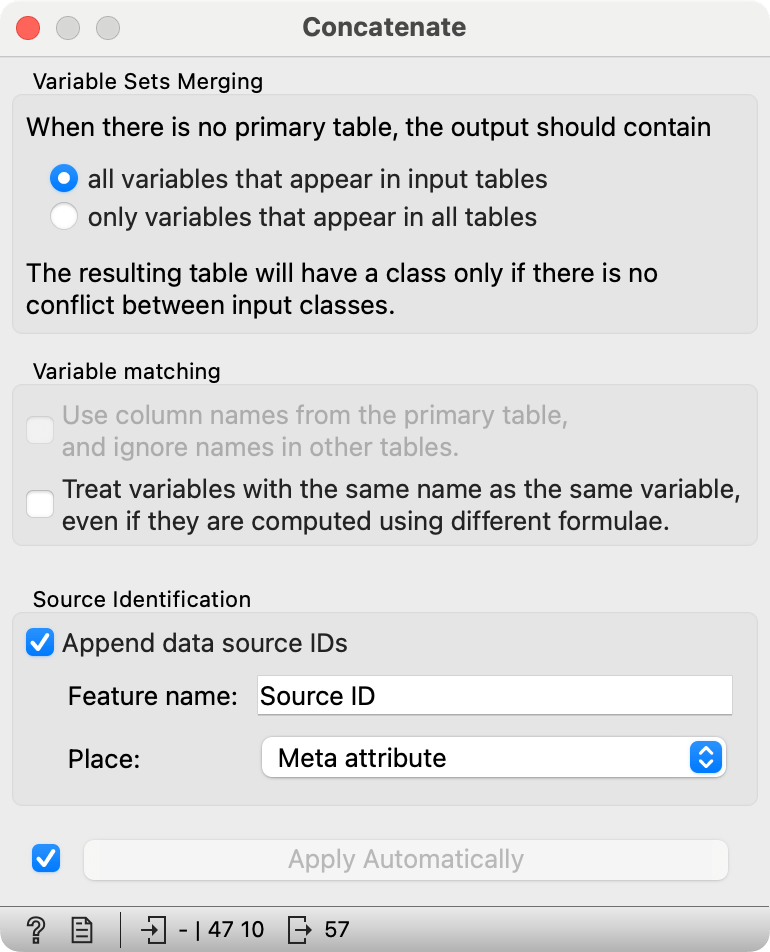
The Neighbors widget only outputs neighbors, so we have to use Concatenate to join the candidate documents to the newly found neighbors. We will also add the source information to know which documents come from the query and which are the neighbors, and add the information to meta variables.
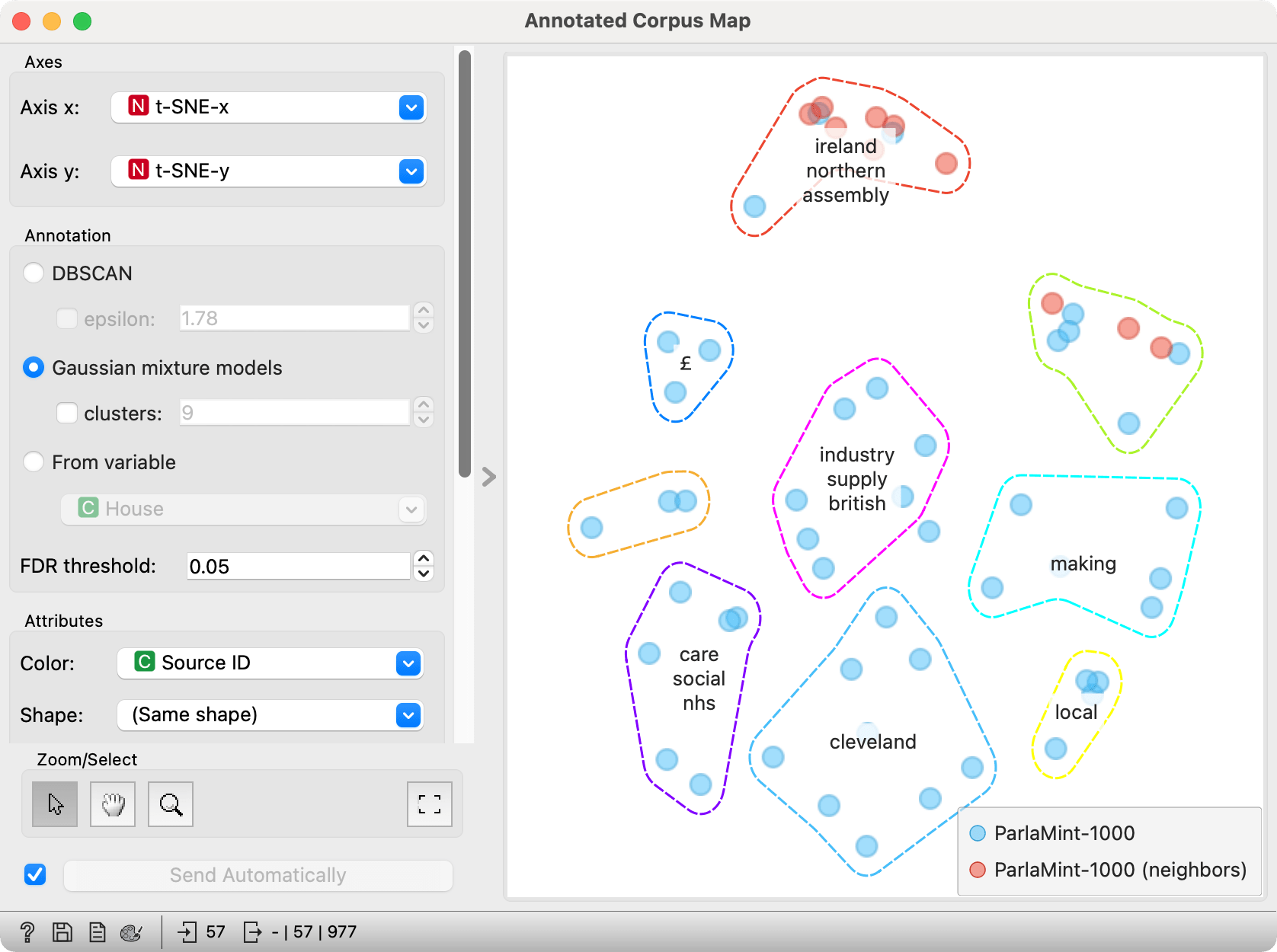
Next, we have to pass the data to yet another Corpus, because Concatenate output a Table, not a Corpus object. In Corpus (1) we once again set the text variable to content. Then we pass the data to t-SNE, an embedding technique that maps documents in space based on the previously computed document embeddings. Finally, we pass the data to Annotated Corpus Map to discover document clusters and characterize them with representative words. Voila, a 2D dimensional map, where the dots represent the documents and their color their origin -- whether they were our candidate document or the found neighbor. It looks like most of the neighbors refer to the Northern Ireland. Typically, these refer to the progress in passing bills concerning Northern Ireland.
Do it better
The full workflow is available for download in the Examples page.
This workflow, naturally, captures only a small part of the technique proposed by Huijnen et al. Most notably, neighbor search is based on entire documents, not just sentences that contain mentions of "progress". Sentence extraction could be achieved with the dedicated Python Script from our Scripts repository. Afterwards, filtering on sentences that contain only the word "progress" has to be repeated.
Next, UMAP functionality is still missing in Orange. t-SNE is still a good substitute for UMAP for producing 2D data maps.
Finally, observing instances through time is a bit cumbersome in Orange, but could be achieved with the Time Slice widget from the Timeseries add-on. For that, we would of course need a much bigger data set, not only 47 candidate speeches.
The good news is that the functionality is fully available in the Jupyter notebooks from the Semantics of Sustainability group's Github page. I was ever so glad to meet another group that believes in open science as much as we do!